

文章最后更新时间:2025年06月11日已超过382天没有更新。
前言
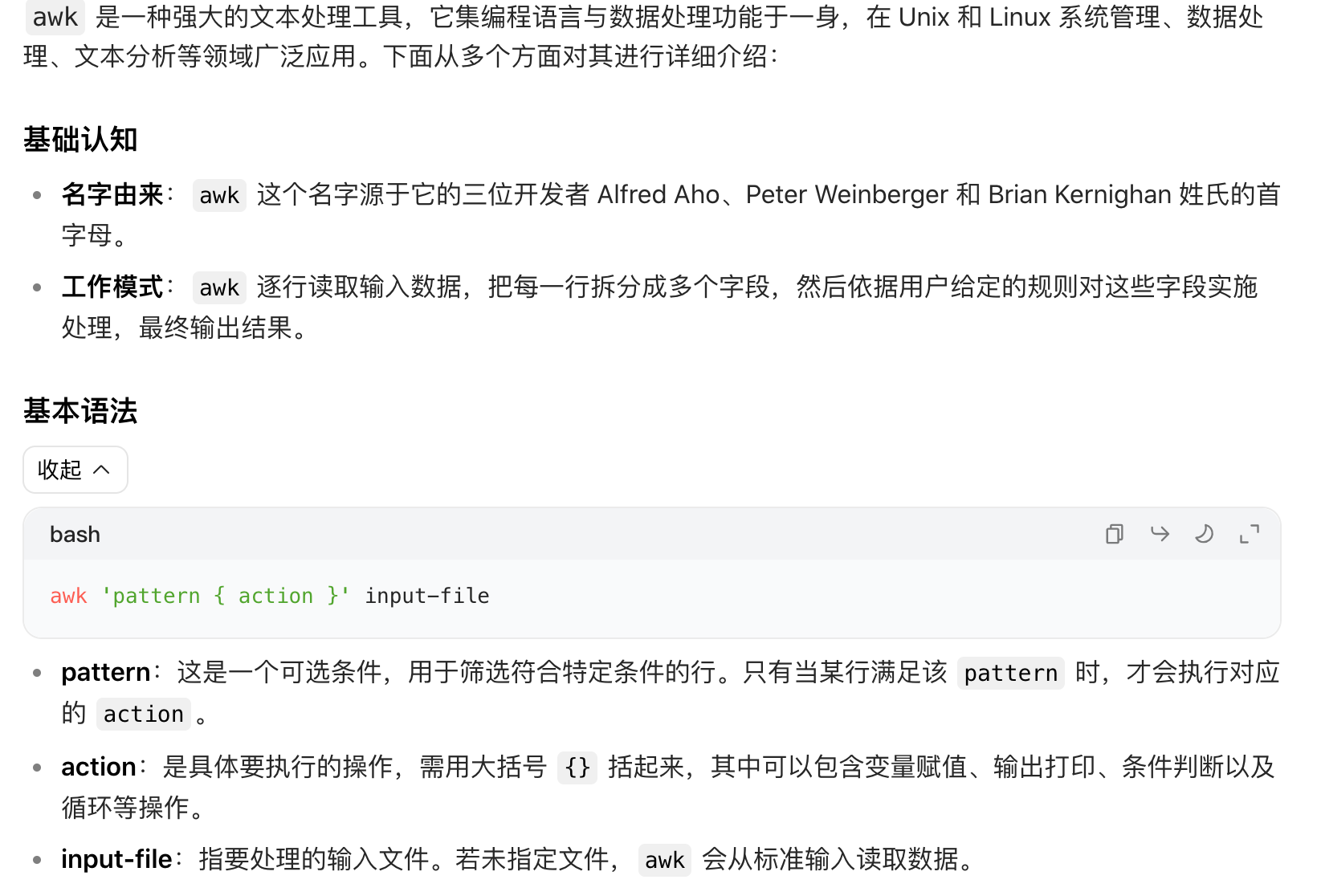
常见内置变量
$0:代表当前正在处理的整行内容。
$1, $2, ...:分别表示当前行的第 1 个字段、第 2 个字段,依此类推。
NF:表示当前行的字段数量。
NR:表示当前处理的行号。
FS:输入字段分隔符,默认是空格或制表符,可通过 -F 选项或在 awk 脚本里修改。
OFS:输出字段分隔符,默认是空格。
实战训练
基础字段提取
[ldx@VM-20-5-opencloudos ~]$ cat test.txt
John 25 Engineer
Alice 30 Manager
Bob 22 Developer
# 输出整行
[ldx@VM-20-5-opencloudos ~]$ awk '{print $0}' test.txt
John 25 Engineer
Alice 30 Manager
Bob 22 Developer
# 输出所有字段(无分隔符)
[ldx@VM-20-5-opencloudos ~]$ awk '{print $1 $2 $3}' test.txt
John25Engineer
Alice30Manager
Bob22Developer
# 自定义输出格式
[ldx@VM-20-5-opencloudos ~]$ awk '{print "姓名:"$1,"年龄:"$2,"职位:"$3}' test.txt
姓名:John 年龄:25 职位:Engineer
姓名:Alice 年龄:30 职位:Manager
姓名:Bob 年龄:22 职位:Developer
姓名: 年龄: 职位: # 最后一行可能为空行
分隔符修改与指定
[ldx@VM-20-5-opencloudos ~]$ cat test.txt
John 25 Engineer
Alice 30 Manager
Bob 22 Developer
# 使用 sed 将空格替换为 #
[ldx@VM-20-5-opencloudos ~]$ sed -i 's/ /#/g' test.txt
[ldx@VM-20-5-opencloudos ~]$ cat test.txt
John#25#Engineer
Alice#30#Manager
Bob#22#Developer
# 未指定分隔符时,# 被视为字段内容
[ldx@VM-20-5-opencloudos ~]$ awk '{print $1,$2}' test.txt
John#25#Engineer
Alice#30#Manager
Bob#22#Developer
# 通过 -F 指定分隔符为 #
[ldx@VM-20-5-opencloudos ~]$ awk -F '#' '{print $1,$2}' test.txt
John 25
Alice 30
Bob 22
行号过滤与字段提取
# 打印第 2-3 行
[ldx@VM-20-5-opencloudos ~]$ awk 'NR==2,NR==3' test.txt
Alice#30#Manager
Bob#22#Developer
# 读取系统文件并打印 18-21 行(含行号)
[ldx@VM-20-5-opencloudos ~]$ cat /etc/passwd > test.txt
[ldx@VM-20-5-opencloudos ~]$ awk 'NR==18,NR==21{print NR,$0}' test.txt
18 polkitd:x:997:997:User for polkitd:/:/sbin/nologin
19 rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
20 rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
21 avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
# 打印第一列、倒数第二列、最后一列(以 : 分隔)
[ldx@VM-20-5-opencloudos ~]$ awk -F ':' '{print $1,$(NF-1),$NF}' test.txt
root /root /bin/bash
bin /bin /usr/sbin/nologin
daemon /sbin /usr/sbin/nologin
...(省略中间行)...
lighthouse /home/lighthouse /bin/bash
ldx /home/ldx /bin/bash
网络地址与输出分隔符设置
# 获取 eth0 接口的 IP 地址
[ldx@VM-20-5-opencloudos ~]$ ifconfig eth0 | awk 'NR==2{print $2}'
10.0.20.5
# 通过 -v 选项设置 OFS 输出分隔符
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" -v OFS="---" '{print $1,$(NF)}' test.txt
root---/bin/bash
bin---/usr/sbin/nologin
daemon---/usr/sbin/nologin
...(省略中间行)...
lighthouse---/bin/bash
ldx---/bin/bash
# 设置 OFS 为制表符
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" -v OFS="\t" '{print $1,$(NF)}' test.txt
root /bin/bash
bin /usr/sbin/nologin
daemon /usr/sbin/nologin
...(省略中间行)...
awk 变量
内置变量图示
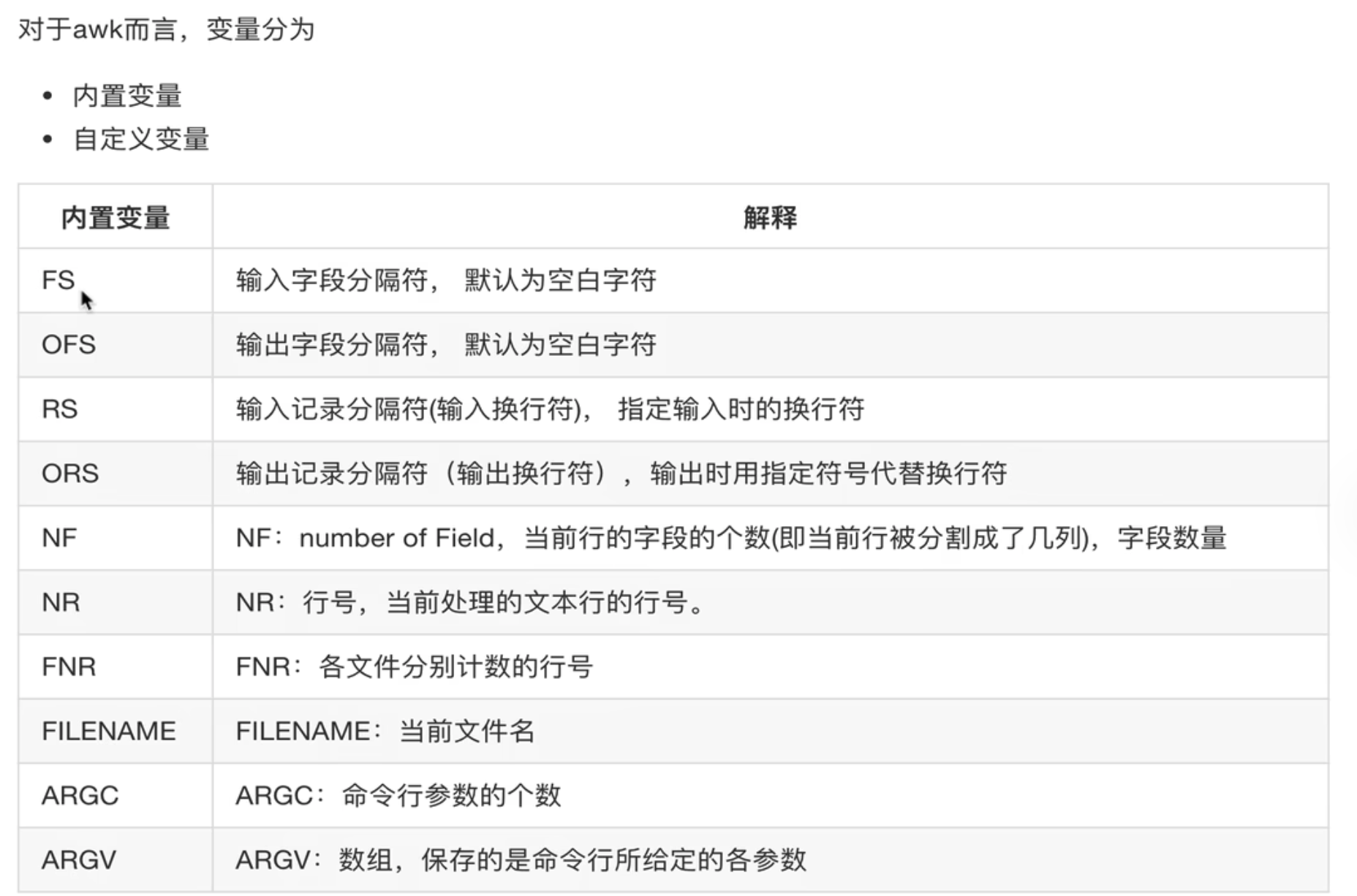
变量使用示例
# FS:设置输入分隔符为 :
[ldx@VM-20-5-opencloudos ~]$ awk -v FS=":" '{print $1}' test.txt
root
bin
daemon
# FNR:文件内相对行号(多文件场景)
[ldx@VM-20-5-opencloudos ~]$ awk '{print FNR $0}' test.txt system_log.txt
1root:x:0:0:Super User:/root:/bin/bash
2bin:x:1:1:bin:/bin:/usr/sbin/nologin
...(test.txt 行号 1-11)...
1[2024-01-01 10:00:00] INFO: System started successfully.
2[2024-01-01 10:05:00] WARN: Disk space is low...
# RS:修改输入换行符(以 : 分割内容)
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" -v RS=":" '{print NR $1}' test.txt
1root
2x
30
...(按 : 分割后逐行输出)...
# ORS:修改输出换行符(用 ---- 替代)
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" -v ORS="------" '{print NR $1}' test.txt
1root------2bin------3daemon------...(连续输出无换行)...
# FILENAME:获取当前处理的文件名
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" '{print FILENAME,$1}' test.txt
test.txt root
test.txt bin
test.txt daemon
# ARGV:获取命令行参数
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" '{print ARGV[0],ARGV[1],ARGV[2]}' test.txt system_log.txt
awk test.txt system_log.txt
awk test.txt system_log.txt
...(每行都输出参数)...
# 自定义变量
[ldx@VM-20-5-opencloudos ~]$ awk -v myname="刘霸天" 'BEGIN{print"我的名字是?" myname}'
我的名字是?刘霸天
awk 模式
空模式(处理所有行)
[ldx@VM-20-5-opencloudos ~]$ awk '{print $0}' test.txt
root:x:0:0:Super User:/root:/bin/bash
bin:x:1:1:bin:/bin:/usr/sbin/nologin
...(输出所有行)...
正则表达式模式
# 匹配包含字母 a 的行
[ldx@VM-20-5-opencloudos ~]$ cat input.txt
apple
banana
cherry
date
[ldx@VM-20-5-opencloudos ~]$ awk '$0 ~ /a/' input.txt
apple
banana
date
# 匹配不包含字母 a 的行
[ldx@VM-20-5-opencloudos ~]$ awk '$0 !~ /a/' input.txt
cherry
关系表达式模式
# 筛选成绩大于 80 分的学生
[ldx@VM-20-5-opencloudos ~]$ cat scores.txt
Alice 85
Bob 70
Charlie 90
David 65
[ldx@VM-20-5-opencloudos ~]$ awk '$2>80 {print $0}' scores.txt
Alice 85
Charlie 90
范围模式(匹配区间行)
# 匹配日志开始到结束的行
[ldx@VM-20-5-opencloudos ~]$ cat log.txt
Start of log
Line 1
Line 2
End of log
Another line
[ldx@VM-20-5-opencloudos ~]$ awk '/Start of log/,/End of log/' log.txt
Start of log
Line 1
Line 2
End of log
BEGIN 和 END 模式
# 统计成绩总和
[ldx@VM-20-5-opencloudos ~]$ awk 'BEGIN {sum = 0} {sum += $2} END {print "Total score:", sum}' scores.txt
Total score: 310
组合模式(逻辑运算符)
# 筛选成绩在 70-90 分之间的学生
[ldx@VM-20-5-opencloudos ~]$ awk '$2>70 && $2<90 {print $0}' scores.txt
Alice 85
格式化输出
print 与 printf 对比
printf 格式控制示例
# 基础格式化输出
[ldx@VM-20-5-opencloudos ~]$ cat data.txt
John 25
Alice 30
Bob 22
[ldx@VM-20-5-opencloudos ~]$ awk '{printf "Name: %s, Age: %d\n", $1, $2}' data.txt
Name: John, Age: 25
Name: Alice, Age: 30
Name: Bob, Age: 22
# 表格化输出系统用户信息
[ldx@VM-20-5-opencloudos ~]$ awk -F ":" '
BEGIN{
printf "%-15s\t %-15s\t %-15s\t %-15s\t %-15s\t %-15s\t %-15s\n",
"用户名", "密码", "UID", "GID", "用户注释", "用户家目录", "用户使用的解释器"
}
{
printf "%-15s\t %-15s\t %-15s\t %-15s\t %-15s\t %-15s\t %-15s\n",
$1, $2, $3, $4, $5, $6, $7
}' test.txt
用户名 密码 UID GID 用户注释 用户家目录 用户使用的解释器
root x 0 0 Super User /root /bin/bash
bin x 1 1 bin /bin /usr/sbin/nologin
...(省略中间行)...
总结
- print:输出格式简单,由
OFS控制字段分隔,自动添加换行符。 - printf:通过格式化字符串(如
%-15s左对齐、%d整数)实现精细排版,需手动添加换行符\n。
文章版权声明:除非注明,否则均为柳三千运维录原创文章,转载或复制请以超链接形式并注明出处。



